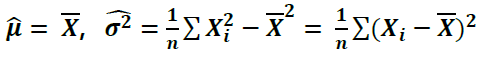이 포스트는 K-MOOC 숙명여대 여인권 교수님의 통계학의 이해 Ⅱ 강의를 기반으로 작성되었습니다.
지난 글에서 추론 목적에 따라 통계적 추론을 분리하는 방법 중 추정하는 방식에서 점추정 방법이 있었다. 이번에는 이 점추정량을 어떻게 구하는지, 어떤 성질을 가져야 되는지 등을 알아보고자 한다.
점추정
미지의 모수를 표본의 어떤 함수(=통계량: 미지의 모수를 포함하지 않는 표본에 의해 얻어질 수 있는 정보로만 이뤄진 값)를 통해 어떤 값으로 추정하는 과정 추정방법: 적률법, 최대가능도추정법, 최소제곱법 등
적률법 (Method of Moments) 우선 적률법은 E(X^k)로 나타내는 모멘트를 이용하는 것인데, 대부분 확률분포에서 모수는 기댓값으로 표시한다는 근거로부터 나오게 되었다. 예를 들어, N(μ,σ^2)인 정규분포에서 모수를 모멘트로 표현하면 μ=E(X), σ^2=E(X^2)-E(X)^2이 된다. 여기에서 표본 n개를 얻었다면, n개를 이용하여 E(X)와 E(X^2) 값을 알면 μ과 σ^2을 다음과 같이 추론할 수 있을 것이다.
적률법을 이용한 모평균과 모분산 추론
모멘트 (Moments) 함수 값들이 분포하는 모양을 정량적으로 측정하는 방법 k차 모멘트를 E(X^k)로 나타내며 1차 모멘트는 기댓값인 E(X)가 된다.
왜 적률법에서는 분산을 n-1로 나눠주지 않을까? 앞에서 분산을 계산할 때는 편차를 이용해서 자유도가 n-1이기 때문에 분모를 n-1로 나눠 구한다고 배웠다. 하지만 여기 적률법에서는 n으로 나눠준 것을 볼 수 있다. 이는 뒤에서 배우겠지만, 비편향 성질을 이용하기 때문에 n으로 나눠주는 것이다. 기준에 따라 우리가 추정하는 통계값이 바뀔 수도 있다는 사실을 알아두자!
최대가능도추정법 최대가능도추정법은 R. A. Fisher가 제안한 방법으로, 우선 가능도(likelihood, 우도)에 대해 알아야 한다. (아래 참고) 이는 최대가능도추정량(MLE, Maximum Likelihood Estimator)을 가지는 θ를 추정하는 것이다. 이를 구하기 위해서는 가능도 함수인 L(θ; x)를 사용하며, 이는 확률질량(밀도)함수인 f(x; θ)와 동일하다. 이 때 가능도는 θ에 대한 함수라 x값이 고정되어 있고, 확률질량(밀도)함수는 x에 대한 함수라 θ값이 고정되어 있다. 일반적으로 가능도 함수에 로그를 씌운 로그가능도함수를 통해 계산한다.
최대가능도추정법을 계산하기 위한 가능도함수
가능도 (likelihood, 우도) 해당 관측값을 얻을 가능성이 얼마나 되는지를 나타내는 척도 가능도 예시
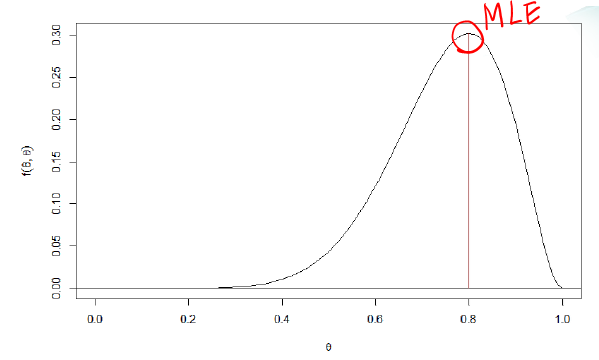
해당 예시를 그래프로 그리면 다음과 같다.
가능도 그래프
여기에서 최대가능도추정량(MLE, Maximum Likelihood Estimator)이란 가능도가 가지는 최댓값, 최대 높이의 위치 θ를 의미한다. 또한 그래프의 기울기인 곡률(curvature)로 모수에 대한 자료가 얼마나 많은지 그 정보량(information)을 나타낸다.
베이지안 추론에서의 가능도 함수 사후분포에 관심을 가지는 베이지안 추론은 사전분포 * 확률질량(밀도)함수와 비례하다고 나타낸다. 위에서 확률질량(밀도)함수는 가능도 함수와 동일하다고 했으므로 만약 사후분포를 θ의 관점에서 본다면 이는 사전분포 * 확률질량(밀도)함수와 비례하다고도 나타낼 수 있다. 베이지안 추론
이외에도 최소제곱법 등으로 점추정량을 계산하는데 분포가 복잡해지면 값을 구하기 어려우므로 직관적으로 구하는 경우도 상당히 있다. 통상적으로 점추정량과 모수가 일치할 가능성은 거의 없지만 구간추정이나 가설검정에서 핵심적인 기준 통계량으로 사용된다.
직관적인 추정량
추정량(estimator)과 추정치(estimate) 추정량(estimator) : 확률변수 추정치(estimate) : 실제 관측값
좋은 추정량 판단 기준
일치성 (consistency) 표본크기 n이 커지면 모수가 추정량에 수렴하는지 큰수의 법칙(대수의 법칙)으로 판단한다. 예를 들어 모평균 μ값을 추정할 때 표본평균을 사용하는 것이며, 이러한 것을 convergence in probability라고 표현한다.
비편향성 (unbiasedness, 불편성) 편향(편의, bias)이 없어야한다는 것으로, 여기에서 편향이란 추정량의 기댓값과 실제값의 차이를 말한다. 편향이 0이면 비편향이므로 이때의 추정량을 비편향 추정량이라고 부른다. 예를 들어 표본평균의 기댓값은 모평균 μ과 같으므로 표본평균은 비편향 추정량인 것이고, 표본분산(or 표준편차)을 구할 때 n이 아닌 n-1로 나눠준 이유 중 하나도 비편향 추정량으로 만들기 위함이다. 그러나 표본표준편차의 기댓값을 취한 값 E(S) ≠ σ이므로 편향(편의) 추정량이다.
편향 (bias)
효율성 (efficiency) 두 추정량이 있을 때 어떤 것이 더 좋은지 비교할 때 사용하는 것이다. 대표적인 비교 기준으로는 MSE(mean square error)가 있으며, MSE 식을 정리해보면 분산과 편향을 제곱한 값을 더한 것으로 표현할 수 있다. 또한 MSE 값이 작을수록 더 효율적이다.
효율성 (efficiency)
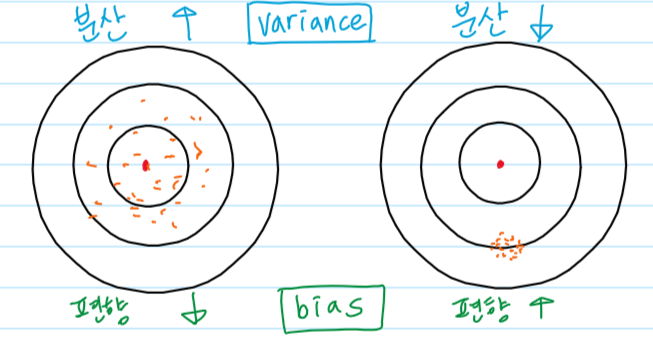
분산(variance)과 편향(bias) 분산은 흩어져 있는 정도를 나타내고, 편향은 치우쳐져 있는 정도를 나타낸다. 가장 대표적인 예시 그림으로 과녁 그림이 있는데 중심에는 가깝지만 퍼져 있으면 분산(variance)이 높은 것이며, 중심과는 떨어져있지만 서로 모여있으면 편향(bias)이 높은 것이다. 분산(variance)과 편향(bias)