이 포스트는 책 '한국어 임베딩(자연어 처리 모델의 성능을 높이는 핵심 비결 Word2Vec에서 ELMo, BERT까지, 이기창 저)'을 기반으로 작성되었습니다.

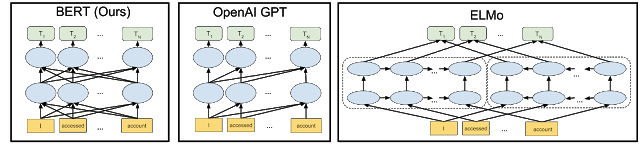
구글에서 공개한 모델인 BERT는 앞에서 소개했던 트랜스포머 블록을 사용하고 bi-directional하기 때문에 좋은 성능을 내어 많이 사용되고 있다.
(논문 pdf : https://arxiv.org/pdf/1810.04805.pdf)
이전 다른 모델들(GPT, ELMo)과 BERT를 비교해보자.
GPT는 주어진 sequence로 다음 단어를 예측하는 언어 모델이라서 단어 sequence를 한 방향으로만 보는 아키텍쳐를 지니고 있으며, ELMo는 bi-LSTM layer 상단은 양방향이지만 중간 layer는 한 방향으로 학습되는 모델이다.
반면에 BERT 모든 layer에서 양방향으로 학습된다. 같은 BERT 모델이라도 pre-train 시 한 방향만 보는 경우 성능이 감소되기에, 모델이 양방향 전후 문맥을 모두 보는 것은 성능 면에서 중요하게 여겨진다.
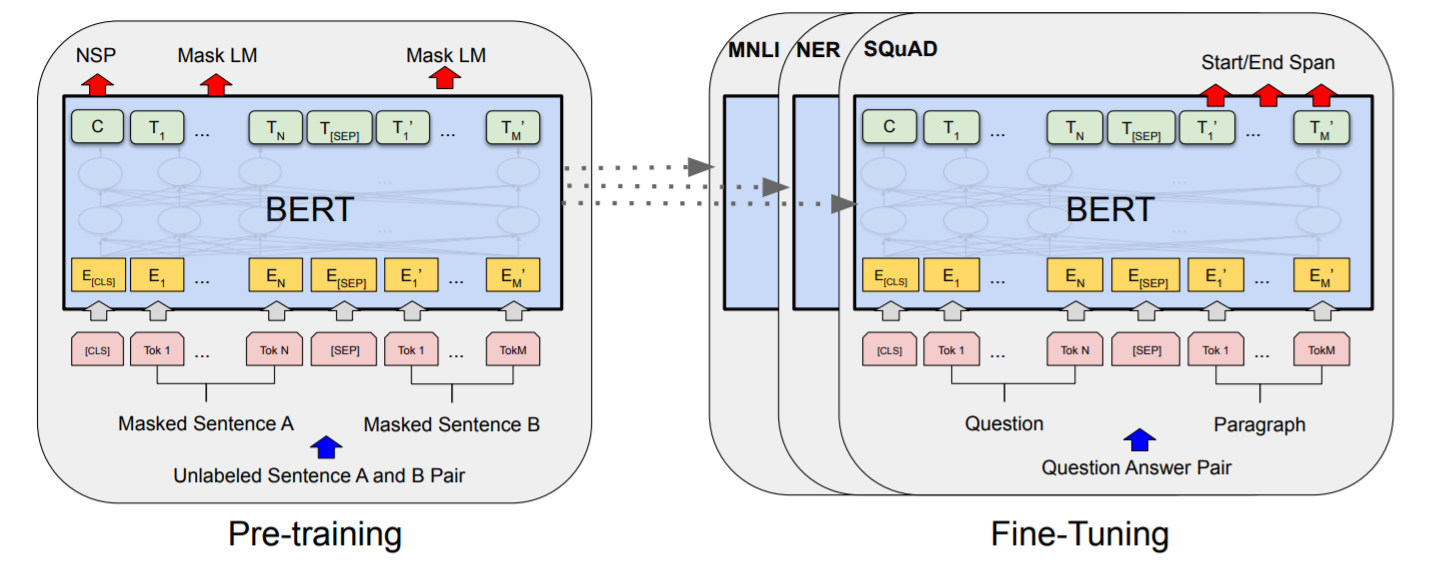
BERT의 pre-train task
BERT가 미리 진행할 pre-train task에는 마스크 언어 모델과, NSP(Next Sentence Prediction) 두 가지가 있다.
각각을 수행하기 위해 어떤 데이터가 필요한지, 이를 통해 만들어낼 수 있는 결과에 대해 알아보자.
- 마스크 언어 모델 : 문장 전체를 모델에 알려주고, 빈칸(mask)에 해당하는 단어를 예측하는 모델
- 전체 문장 token의 15%를 masking한 후,
실제 빈칸 80%, 다른 token으로 랜덤 할당 10%, 기존 token 그대로 10%로 데이터를 수정 - 실제 빈칸 80% → 모델이 빈칸 채움 → 앞뒤 문맥 읽어낼 수 있음
- 나머지 20% → 모델이 정답 token이 무엇일지 맞춤 → token 사이의 의미, 문법적 관계 도출
- 전체 문장 token의 15%를 masking한 후,
- NSP (Next Sentence Prediction) : 다음 문장인지 여부 맞추기
- 학습 데이터는 1건 당 문장 2개로 구성
: 동일 문서에서 실제 이어지는 문장 2개 50% (True), 서로 다른 문서에서 뽑은 문장 2개 50% (False)
→ 이어지는 문장 여부를 반복 학습하며 문장간 의미관계 도출 가능 - max_num_tokens 정의 후,
max_sequence_length == max_num_tokens가 되는 데이터 90%,
max_sequence_length > max_num_tokens가 되는 데이터 10%가 되도록 랜덤 생성
→ 짧은 문장이 성능 저하에 큰 영향 주지 않음 - 문장 2개의 token 총 수가 max_num_tokens 넘지 못하도록 token 수 많은 문장의 맨 앞 또는 맨 뒤 token 제거
(맨 앞일지 맨 뒤일지는 50% 확률로 선택)
→ 일부 문장 성분 없어도 전체 의미 이해 가능
- 학습 데이터는 1건 당 문장 2개로 구성
이러한 두 pre-train task를 통해 학습되어 있는 상태에서, 각자 downstream task에 맞게 fine-tuning하여 모델을 이용할 수 있다.
BERT 모델 구조
우선, BERT 모델 입력을 위해 필요한 4가지 special token은 다음과 같다.
- [CLS] : 문장 시작 토큰
- [SEP] : 문장 끝 토큰
- [MASK] : 마스크 토큰
- [PAD] : 배치 데이터 길이 맞추기용 토큰
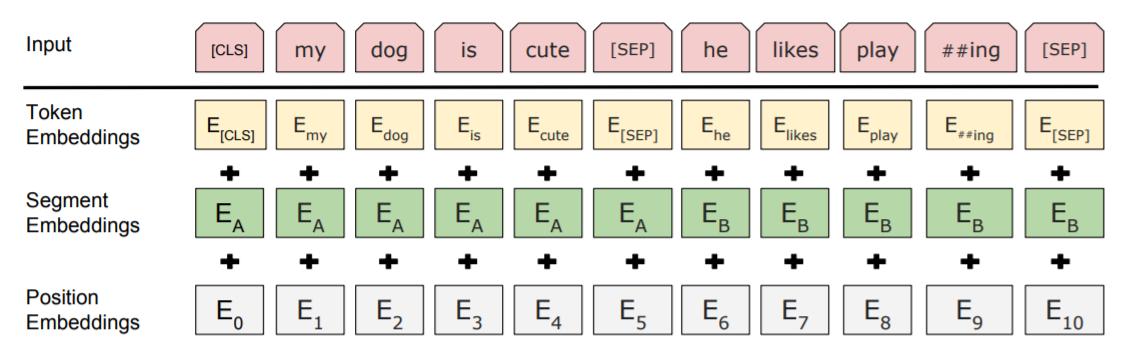
입력 layer는 위 사진처럼 3가지 임베딩을 더하여 생성된다.
각 임베딩은 다음과 같으며, 이를 만들기 위해 필요한 행렬은 학습되며 계속 업데이트된다.
- Token Embedding : 입력 token 자체 나타내는 임베딩
- Segment Embedding : 첫번째 문장인지 두번째 문장인지 나타내는 임베딩
- Position Embedding : 입력 문장 내 절대적 위치 나타내는 임베딩
이 임베딩 값들을 더해 layer normalization을 한 뒤, dropout을 통해 첫번째 입력 행렬을 구성한다.
이 행렬의 크기는 (token 개수) * (hidden 차원 수)가 된다.
활성함수는 기존 트랜스포머 블록에서 사용하던 ReLU 대신 GELU를 사용하며, 이는 정규분포 누적분포함수를 사용하여 0 주변에서 상대적으로 smooth하게 변해 학습 성능이 높아지게 만들어준다.
BERT 모델은 기본 모델과 라지 모델이 있는데, 이는 토큰 임베딩 차원 수나 트랜스포머 블록 개수 등에서 차이가 난다.
| BERT | 기본 모델 | 라지 모델 |
| 트랜스포머 블록 내 Multi-Head Attention Layer의 토큰 임베딩 크기 |
768차원 | 1024차원 |
| 트랜스포머 블록 개수 | 12개 | 24개 |
기존 트랜스포머와 BERT의 가장 큰 차이점은 pre-train 과제를 수행하기 위한 마지막 prediction 단(layer)이라고 할 수 있다.
마스크 언어 모델은 마지막 트랜스포머 블록의 마스크([MASK]) 위치에 해당하는 토큰 벡터를 input tensor로 넣고 입력 당시와 동일한 차원 수로 선형변환한 뒤 layer normalization를 수행한다.
NSP는 마지막 트랜스포머 블록의 마스크([MASK]) 위치와 첫번째 토큰([CLS])에 해당하는 토큰 벡터를 input tensor로 넣는다.
그리고 logit vector (= (변환한) input tensor * output_weights + output_bias)를 생성하고, 다른 딥러닝 아키텍쳐처럼 softmax를 취한 확률 vector와 정답을 비교해서 cross entropy를 구하고 이를 최소화하기 위해 모델 parameter를 업데이트시킨다.
BERT를 pre-train시키기 위해서는 여러 GPU가 필요하고 많은 시간이 소모된다.
그래서 아래 링크와 같이 이미 공개되어 있는 모델이 있으므로 이를 이용하여 사용할 수 있다.
https://github.com/yeontaek/BERT-Korean-Model
'DATA SCIENCE > NLP' 카테고리의 다른 글
| [NLP] Transformer Network (1) | 2020.06.23 |
|---|---|
| [NLP] ELMo (Embeddings from Language Models) (0) | 2020.06.23 |
| [NLP] 잠재 디레클레 할당 (LDA) (0) | 2020.06.22 |
| [NLP] Doc2Vec (0) | 2020.05.27 |
| [NLP] 가중 임베딩 (1) | 2020.05.22 |



