이 포스트는 책 '한국어 임베딩(자연어 처리 모델의 성능을 높이는 핵심 비결 Word2Vec에서 ELMo, BERT까지, 이기창 저)'을 기반으로 작성되었습니다.
word2vec, fast text 등 이전까지는 워드 임베딩에 대해 다뤄보았다. 그렇다면 문장을 기준으로는 어떻게 할까?
이러한 단어 임베딩을 문장으로 확장시키는 방법 중에 가중 임베딩이 있다.
(pdf 링크 : https://openreview.net/pdf?id=SyK00v5xx)
가중 임베딩 방식에는 '문서 안의 단어는 글쓴이가 생각한 주제에 의존한다'는 내용이 기반되어 있다. 즉, 주제에 따라 단어 사용 양상이 달라진다는 것이다.
주제 벡터 c_s가 있을 때, 임의의 단어 w가 나타날 확률은 다음과 같다.
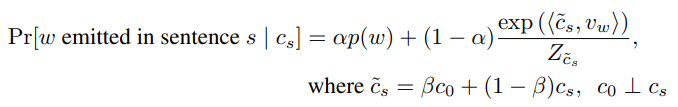
- P(w) : 주제와 상관없이 단어가 등장할 확률
- exp(<v_w, c_s>)/Z : 단어와 주제의 유사도
문장 전체에 대해 계산할 때는 문장에 나오는 단어들에 대해 확률을 모두 곱해서 구한다.

그런데 이는 값이 작아지는 underflow 문제가 나타날 수 있다. 따라서, 아래와 같이 로그를 취해 더하는 방식으로 대체한다.

위의 식을 미분해보면, 다음과 같다.
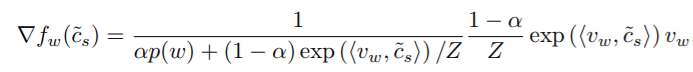
또한 테일러 급수에 의해 아래와 같은 근사식이 나온다.

위의 알파 값을 a=(1-α) / αZ로 변경하고 argmax로 정리하면 다음과 같다.

위 식에 의해 주제 벡터 c_s는 단어 벡터에 가중치를 곱해 만든 새로운 벡터들 합에 비례한다는 것으로 정리할 수 있다.
새로운 단어 벡터를 만들 때 가중치는 P(w)를 고려하여, 즉 해당 단어가 얼마나 자주 등장하는지를 감안하여 지정한다.
희귀한 단어는 높은 가중치를 곱해서 벡터 크기를 늘리고, 자주 등장하는 단어는 낮은 가중치를 곱해서 벡터 크기를 줄인다.
이런 점은 TF-IDF 논리와 비슷하며, 등장 순서를 고려하지 않는 bag of words 원리하고도 비슷하다.
'DATA SCIENCE > NLP' 카테고리의 다른 글
| [NLP] 잠재 디레클레 할당 (LDA) (0) | 2020.06.22 |
|---|---|
| [NLP] Doc2Vec (0) | 2020.05.27 |
| [NLP] Swivel (Submatrix-Wise Vector Embedding Leamer) (0) | 2020.05.18 |
| [NLP] GloVe (Global Word Vectors) (1) | 2020.05.18 |
| [NLP] 잠재 의미 분석 (LSA) (1) | 2020.05.18 |



