이 포스트는 책 '한국어 임베딩(자연어 처리 모델의 성능을 높이는 핵심 비결 Word2Vec에서 ELMo, BERT까지, 이기창 저)'을 기반으로 작성되었습니다.
Doc2Vec이란 이름에서 유추할 수 있듯이, Word2Vec을 문장 단위로 확장한 문서 임베딩 기법이다.
(논문 pdf : https://cs.stanford.edu/~quocle/paragraph_vector.pdf)
Doc2Vec 기법은 문장 전체에 대해 단어 k개씩 슬라이딩해가며 단어 k개가 주어졌을 때 다음 단어를 맞추는 과정을 학습한다.
예를 들어, 'The cat sat on the mat'라는 문장에서 k=3일 때 아래 알고리즘 그림처럼 the, cat, sat으로 on을 예측한다. 이 과정을 한 단어씩 sliding하며 문장 내 모든 단어에 대해 예측하는 과정을 학습하는 것이다.

단어 T개가 있는 문장에서의 로그 확률 평균은 다음과 같다. Doc2Vec은 이 수식을 최대로 만드는 방향으로 train된다.
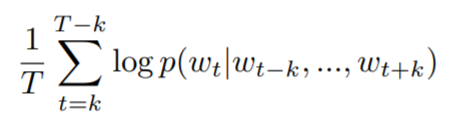
여기에서의 p(w_t | w_t-k, ... , w_t+k)는 다음과 같다.

- w_t : 문장 내 t번째 단어
- y_i : i번째 단어 score
- h : 벡터 반환 함수(평균 or concat)
단어 score인 y는 아래와 같은 수식을 통해 구한다. 단어 임베딩 값이 들어있는 행렬 W에서 해당하는 단어(w_t-k, ... , w_t+k) 값을 참고한 뒤, 함수 h를 통해 벡터화하고 행렬 U에 내적한 뒤 bias vector b를 더한다.
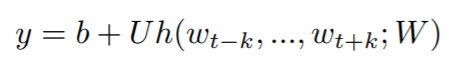
이 과정을 통해 행렬 W가 업데이트되며, 최종적으로 W를 단어의 임베딩으로 사용한다.

다음으로, 앞의 과정을 위의 알고리즘처럼 문서 단위로 확장시키며, 이를 PV-DM(the Distributed Memory Model of Paragraph Vectors)이라고 부른다.
이전에 넣었던 k개 단어와 함께 문서 ID를 넣어 다음 단어를 예측하는 과정으로 학습한다. 문서 ID에 들어갈 벡터는 문서 행렬 D에서 해당 문서 ID에 해당하는 벡터를 참조하여 입력된다.
이 과정을 통해 문서 ID와 함께 단어가 학습되므로, 문서 임베딩이 해당 문서 주제 정보 함축하고 있을 것이다. 또한 단어가 등장하는 순서를 고려하므로 bag-of-words 기법의 단점을 보완한다고 할 수 있다.
지금까지의 과정은 Word2Vec에서의 CBOW 모델과 유사하게 문맥 단어로 타깃 단어를 예측하는 방식으로 진행되었다. 이 과정과는 반대로, Word2Vec의 skip-gram 모델 방식처럼 타깃 단어를 통해 문맥 단어를 예측하는 모델도 있으며, 이는 PV-DBOW(the Distributed Bag of Words version of Paragraph Vector)라고 한다.

'DATA SCIENCE > NLP' 카테고리의 다른 글
| [NLP] ELMo (Embeddings from Language Models) (0) | 2020.06.23 |
|---|---|
| [NLP] 잠재 디레클레 할당 (LDA) (0) | 2020.06.22 |
| [NLP] 가중 임베딩 (1) | 2020.05.22 |
| [NLP] Swivel (Submatrix-Wise Vector Embedding Leamer) (0) | 2020.05.18 |
| [NLP] GloVe (Global Word Vectors) (1) | 2020.05.18 |



