해당 글은 https://kubernetes.io/docs 에 기반하여 작성되었습니다.
django로 데이터를 확인하고 검색하는 api를 개발하는 업무를 하고 있던 중,
"접속량이 많아도 안정적으로 만들어서 사람들이 믿고 쓸 수 있게 하라"는 이야기를 들었다.
어떻게 보면 당연히 해야하는 부분이었지만, 기능 추가에만 집중하고 있었기에 방법을 몰라 너무 막막했었는데..
말로만 듣던 쿠버네티스를 알고 난 뒤 해결의 실마리 일부를 찾을 수 있었다.
이번 글에서는 쿠버네티스가 도대체 무엇이길래 실마리를 줄 수 있었는지 정리하고자 한다.
먼저 쿠버네티스에 대해 다루기 전에 미리 알아야 할 한가지 개념이 있다.
컨테이너 오케스트레이션 (Container Orchestration)
docker 관련 글에서 다루었던 컨테이너에 대해 다시 짚어보자면,
애플리케이션 실행을 위한 코드나 환경 설정 등이 모두 패키징 되어 있는 소프트웨어 표준 단위이다.
애플리케이션 구축을 위해 필요한 모든 것들이 컨테이너 박스에 들어가 있다고 볼 수 있다.
테스트용으로 애플리케이션을 띄운다면 컨테이너 하나만 띄워서 확인하면 되겠지만,
이 애플리케이션을 수백명, 수만명이 이용하려고 접속하면 컨테이너 하나가 감당하지 못하고 그야말로 '서버가 터질' 수도 있다.
만약 그 수많은 접속을 분산 처리해서 관리했다면, 위 같은 무시무시한 케이스를 줄일 수 있을 것이다.
접속이 많아질 때 컨테이너 수를 늘려서 접속량을 분산시키고, 접속이 줄어들면 다시 컨테이너 수를 줄이는 등
컨테이너를 자동으로 관리하는 것이 바로 "컨테이너 오케스트레이션(Container Orchestration)"이다.
(그리고 아래에서 설명하겠지만, 이러한 컨테이너 오케스트레이션 시스템 중 하나가 바로 쿠버네티스인 것이다.)
컨테이너 오케스트레이션 시스템의 주요 기능은 다음과 같다.
- 컨테이너 배포 및 스케줄링
: 여러 서버에 컨테이너를 배포하고, 관리하기 위한 배포 및 스케줄링 전략을 수행한다.
- 배포 전략 : 컨테이너 이미지 업그레이드 / 롤백 등
- 스케줄링 : 리소스 사용량 등을 고려한 컨테이너 자동 배치 - 컨테이너 생명 주기 관리
: 컨테이너 생성부터 실행, 중지, 재시작 등 전반적인 프로세스를 관리할 수 있다. - 서비스 디스커버리 및 로드 밸런싱
: 트래픽이 높으면 로드 밸런싱을 거쳐 여러 서버나 리소스로 분산 처리시킬 수 있다.
(본인에게 필요했던 주요 기능이지 않을까 싶다!) - 저장소 및 네트워크 관리
: 컨테이너에게 필요한 저장소 및 네트워크 자원을 자동으로 할당해주고 관리한다. - 컨테이너 모니터링 및 로그 수집
: Prometheus, Grafana 등을 통해 모니터링을 할 수 있다.
쿠버네티스 (Kubernetes)
앞에서 언급했듯이, 대망의 쿠버네티스는 Google에서 개발한 컨테이너 오케스트레이션 시스템 중 가장 대표적으로 사용되는 오픈소스이다.

컨테이너 오케스트레이션 시스템은 kubernetes 이외에도 docker swarm, apache mesos 등이 있지만
(역시 대기업 Google의 오랜 기간의 운영 노하우가 담겨있어서인지)
docker 옆에 항상 kubernetes가 따라 붙을 정도로 컨테이너 오케스트레이션의 사실상 표준(de-facto standard)으로 쓰이고 있다.
(여담)
쿠버네티스는 k8s로도 많이 불리는데, 이는 kubernetes의 첫 글자 k와 마지막 글자 s, 그리고 그 사이에 8글자가 있다는 의미라고 한다😅
쿠버네티스 오브젝트 (Kubernetes Objects)
먼저 쿠버네티스를 배포하게 되면 cluster라는 것이 생성된다.
이 kubernetes cluster는 node라는 여러 worker machine으로 구성되어 있고, 이 node마다 컨테이너들이 실행되게 된다.

쿠버네티스 구성 요소를 관리하기 위해서는 정의해야 하는 kubernetes objects를 알아야하는데,
대표적인 objects는 다음과 같다.
Pod
컨테이너를 묶는 단위로, 쿠버네티스에서 생성하고 관리하는 배포 가능한 가장 작은 컴퓨팅 단위라고 한다.
우리가 흔히 모임을 부르는 '~~팟'(여행팟, 점심팟, ...) 에서의 팟이랑 비슷한 개념이라고 보면 된다.
하나의 pod 안에 1개 이상의 컨테이너가 들어가고,
같은 pod 안에 있는 컨테이너들은 함께 관리되어 같은 저장소와 네트워크를 공유받아 같은 IP 주소를 할당받게 된다.
컨테이너에 node를 배치할 때도 pod 단위로 진행된다.
그렇기 때문에 하나의 pod 안에 있는 컨테이너들은 같은 node에서 실행된다.
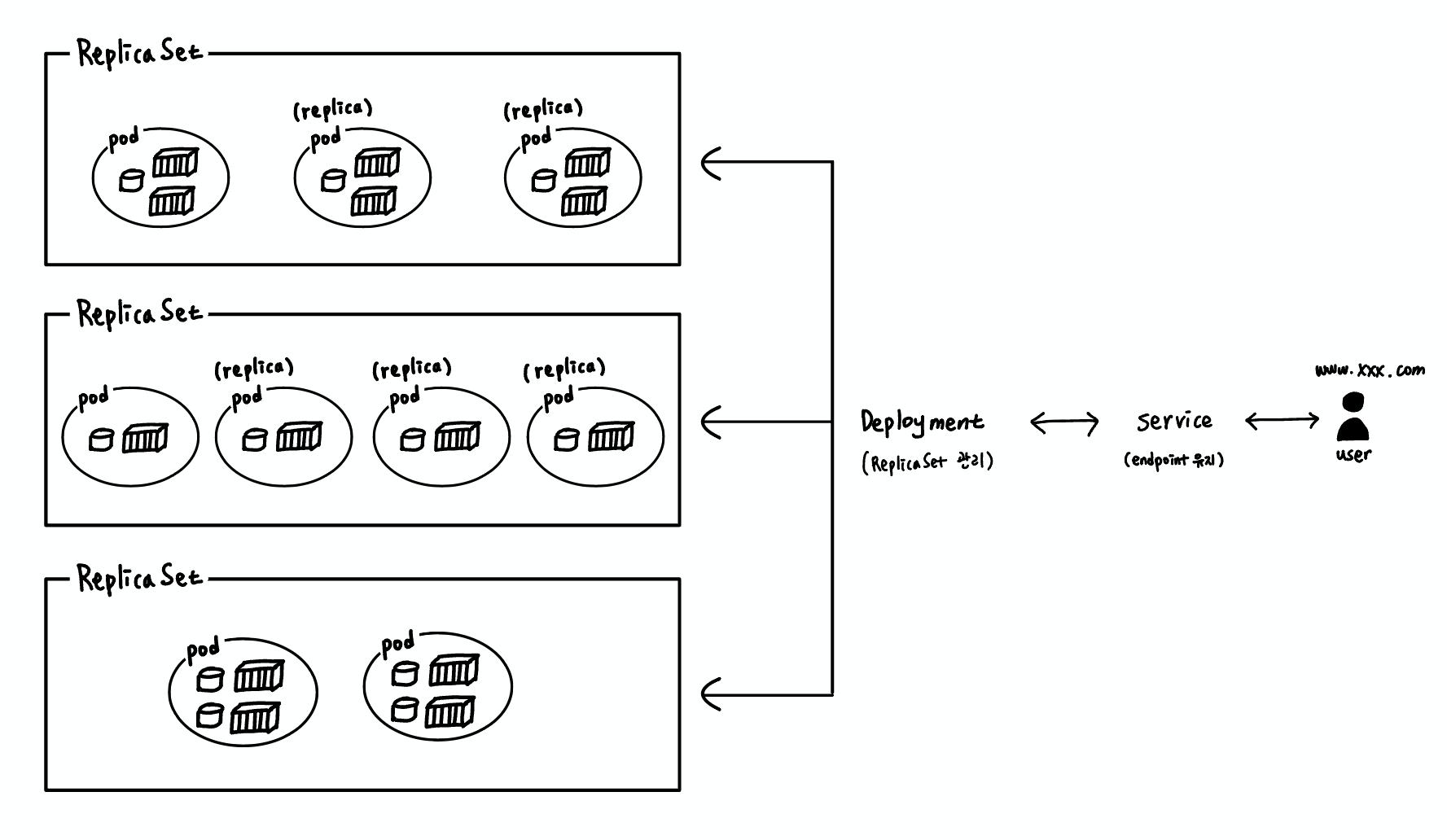
Replica / ReplicaSet
pod의 복제본을 Replica라고 하고, 이 복제본들을 모아놓은 것을 ReplicaSet이라고 한다.
ReplicaSet 설정을 통해 Replica 개수를 지정할 수 있고, 그 개수만큼 pod이 복제되어 Replica가 생성된다.
어떻게 보면 당연한 이야기일 수 있지만.. 이렇게 혹시 모를 상황에 대비해 복제해두기 때문에 가용성(availability)을 보장할 수 있다.
Deployment
여러 ReplicaSet를 관리하는 개념으로,
실제 배포를 할 때 몇개의 ReplicaSet으로 하나의 배포 단위를 구성할지 정의해주는 부분이다.
Service
장애가 발생하거나 새로 업데이트 되어야 할 경우, pod은 언제든지 제거되고 다시 생성될 수 있다.
이럴 때 pod이 변경되면 IP 주소가 바뀌게 되는데, 사용자는 같은 주소에 접속해서 볼 수 있어야 한다.
이런 운영 관리를 하는 것이 service이고, pod 변동으로 인해 IP 주소 등이 변경되더라도
사용자에게는 문제가 없도록 고정된 endpoint를 제공한다.
다음 글에서는 이런 objects를 yaml 파일에 구성하는 방법과, 명령어 등에 대해 알아보고자 한다.
'DATA SCIENCE > DATA ENGINEERING' 카테고리의 다른 글
| [Hadoop] Spark RDD와 DataFrame, 그리고 Dataset (0) | 2025.02.02 |
|---|---|
| [udemy - Apache Spark와 Python으로 빅데이터 다루기] Spark란? (1) | 2024.04.14 |
| [DE] 하둡 없이 맵리듀스를?! Local MapReduce 오픈소스 파헤치기 (0) | 2023.06.17 |
| [DE] 2023 DEVIEW - SCDF로 하루 N만곡 이상 VIBE 메타 데이터 실시간으로 적재하기 (스트림 처리 레거시 극복일지 엿보기) (1) | 2023.06.04 |
| [DE] 개발자들은 어떤 데이터베이스를 많이 사용할까? (2) | 2023.05.07 |



