이 포스트는 CS224W : Machine Learning with Graphs 강의를 기반으로 작성되었습니다.
Graph-level 예측은 전체 그래프의 구조를 나타내는 feature를 기반으로 생성된다.
해당 feature들을 알아보기 전에, kernel 개념에 대해 먼저 알아보고자 한다.
Kernel & Kernel matrix
- Kernel - K(G, G')
: 그래프 간 유사도나 datapoint 간 유사도를 측정하여 실수값을 반환한다. - Kernel matrix
: 모든 datapoint 쌍이나 그래프 쌍 간의 유사도를 측정하는 행렬로,
항상 양수 값(positive eigenvalues)을 가지며 대칭 행렬이다.
Graph Kernel
- 핵심 아이디어 : BoW(Bag-of-Words: 문서에 대한 단어 개수를 feature로 사용)
- 그래프에서는 단어를 node로 간주하여 그래프의 node 개수를 feature로 사용할 수 있다.
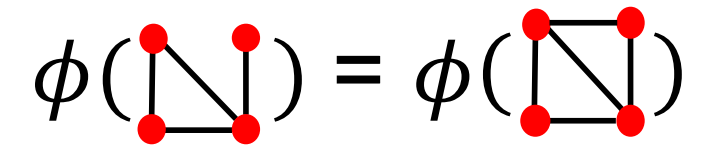
- node 대신 node degree로 한다면, bag of nodes에서는 동일한 feature인 그래프가 서로 다른 feature를 나타낼 수 있다.
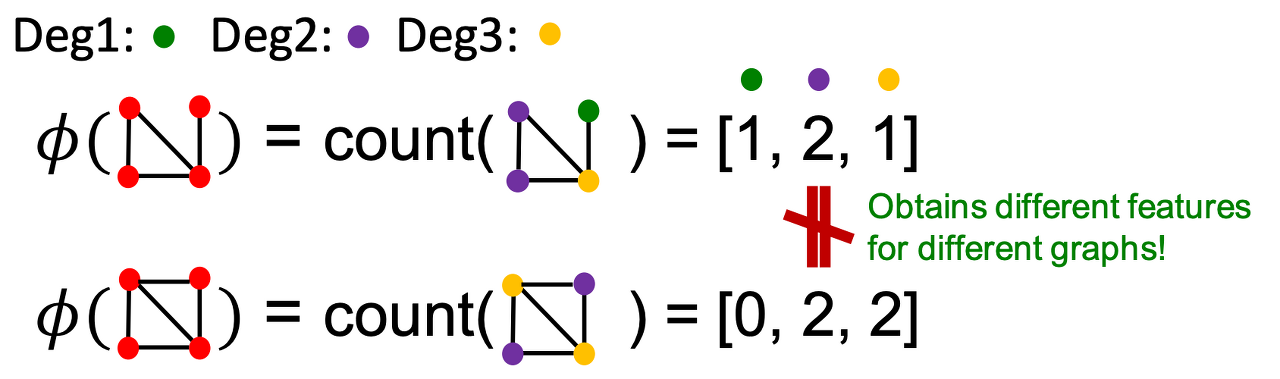
Graphlet Kernel
- 그래프 내 다른 graphlet 개수를 나타내는 feature
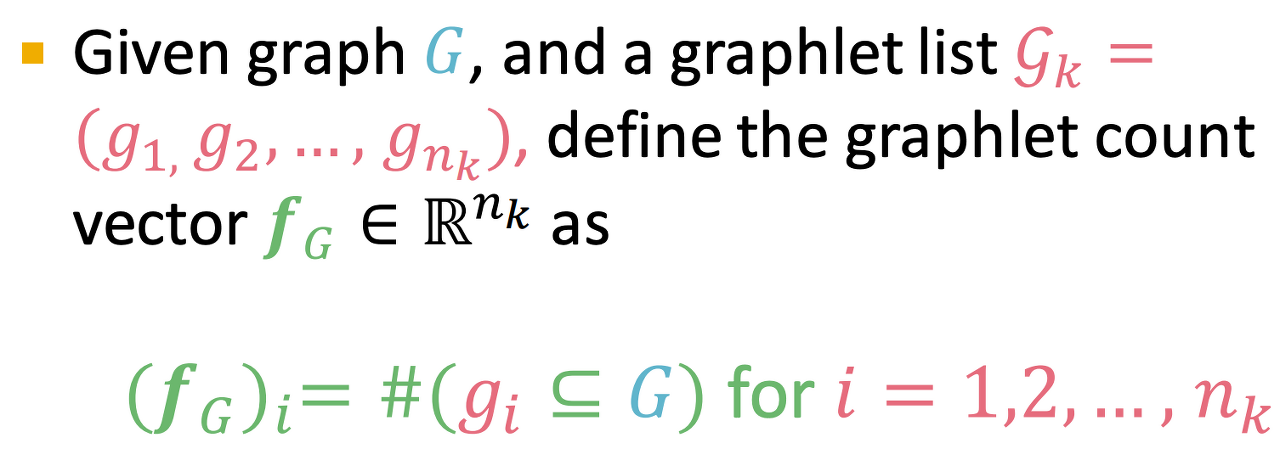
- 예를 들어, k=3이라면 점 3개를 통해 가질 수 있는 graphlet이 해당 그래프에 존재하는 개수를 나타낸다.

- kernel K(G, G')의 경우 두 feature에 대한 내적값으로 구할 수 있다.
- 하지만 graphlet 개수를 세는 비용이 많이 든다는 단점이 있다.
(ex: size n인 그래프에서 size k의 graphlet를 세기 위해서는 n^k번의 계산이 필요하다.)
Weisfeiler-Lehman Kernel
- 효율적인 그래프 설명 feature를 디자인 하는 것을 목표로, 이웃 구조(neighborhood structure)를 사용한다.
- bag of node degrees가 one-hop neighborhood만 보는 local한 정보를 담았다면,
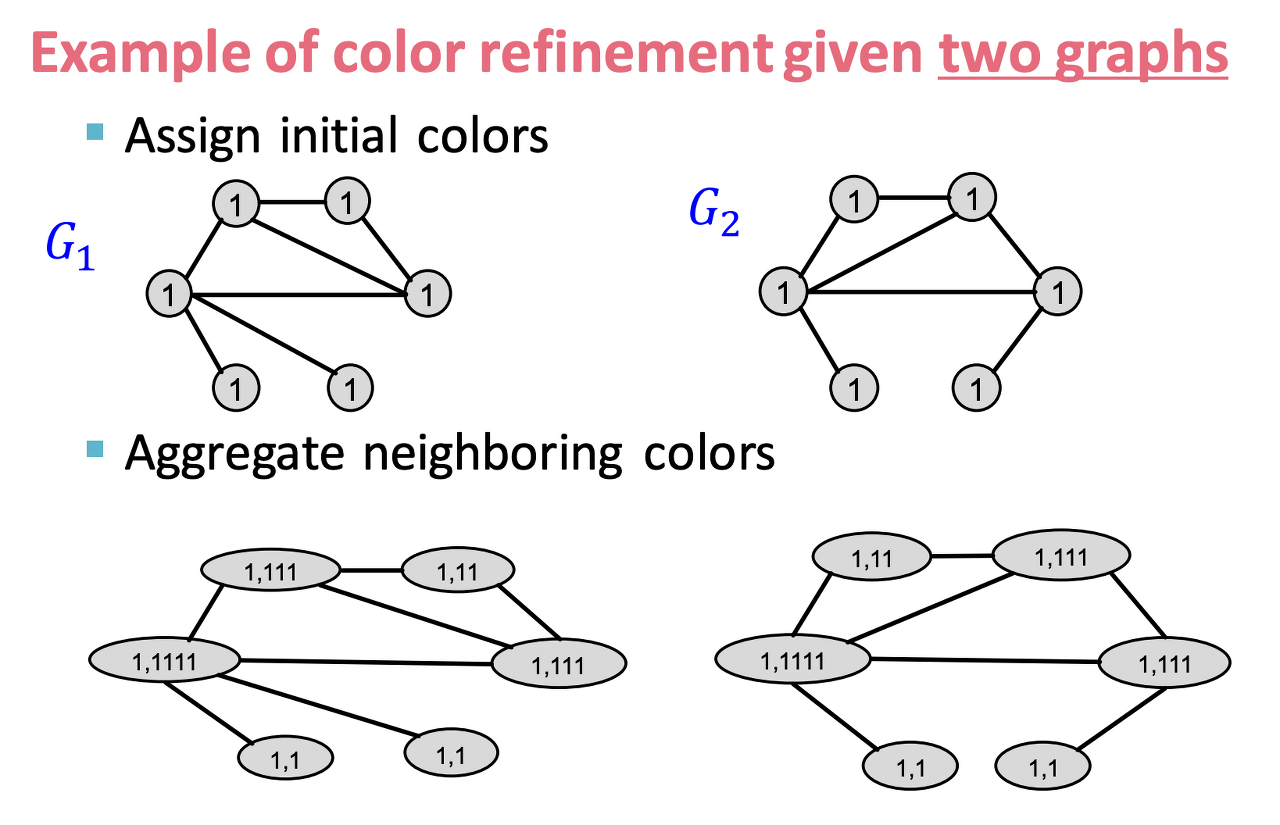
해당 feature는 bag of node degrees의 generalized된 버전으로 볼 수 있다. - 그래프 node에 대한 color refinement를 통해 진행되며, 계산 비용이 적게 든다.
(각 과정에서의 color refinement 복잡도는 link 개수에 linear함) - 과정
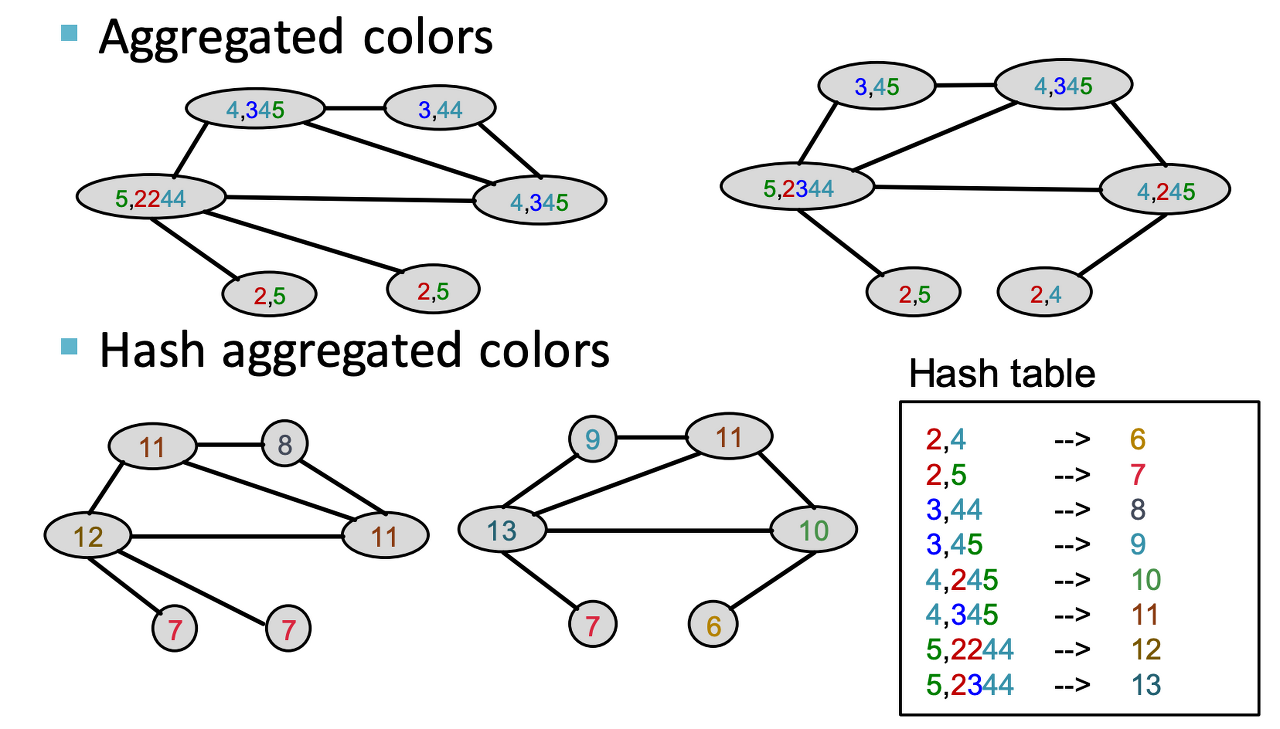
- 초기 color 할당
- 이웃 node에 대한 color 모으기
- hash table에 따라 color 재할당
- 2-3번 과정에 대해 k번 반복
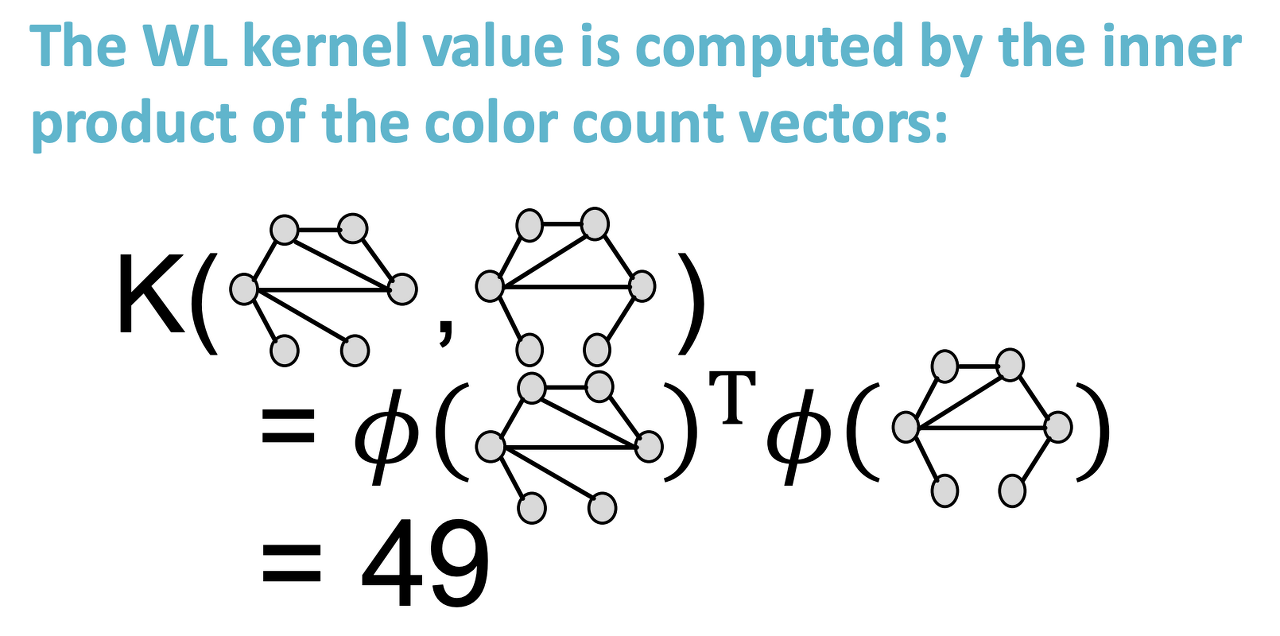
- color별 node 개수 count
- 두 feature에 대한 내적으로 kernel 값 계산


반응형
'DATA SCIENCE > DEEP LEARNING' 카테고리의 다른 글
| [CS224W] 3-1. Node Embeddings (0) | 2022.07.28 |
|---|---|
| [CS224W] 2-2. Link-level Prediction (0) | 2022.07.27 |
| [CS224W] 2-1. Node-level Prediction (0) | 2022.07.26 |
| [CS224W] 1-3. Choice of Graph Representation (0) | 2022.07.24 |
| [CS224W] 1-2. Applications of Graph ML (0) | 2022.07.24 |



