https://wikidocs.net/book/2155를 통해 NLP 공부를 하다가 발견하게 된 pandas_profiling 함수. 보자마자 이런 함수가 있다는걸 진작에 알았더라면 싶었다.
(하지만 설치하는 과정은..... 음..... 🙄)
설치
설치가 프롬프트 창에서 pip로는 불러와지지 않았다. 그래서 해결한 방법!
import sys
!{sys.executable} -m pip install pandas-profiling
결과
(데이터는 한창 준비하고 있는 Kaggle의 Real or Not? NLP with Disaster Tweet 대회 데이터를 이용했다.)
dataTrain = pd.read_csv('train.csv')
pandas_profiling.ProfileReport(dataTrain)첫 화면 Overview에서는 변수 개수, 데이터 개수 및 NA 비율, 변수 타입 개수 등을 볼 수 있다.
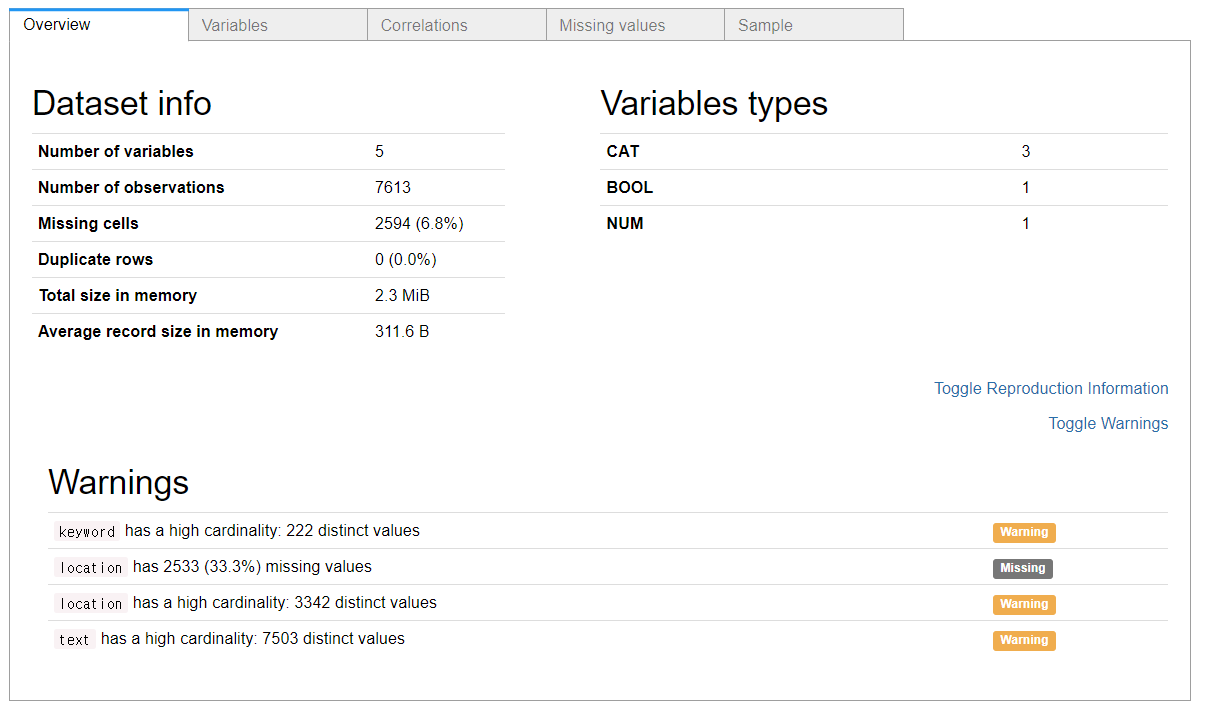
두번째 화면 Variables에서는 각 변수별로 개수 분포 등이 설명되어 있다.

세번째 화면 Correlations는 수치형 변수에 대한 상관분석 (여기에서는 id는 단순한 index이므로 상관관계가 거의 없다.)

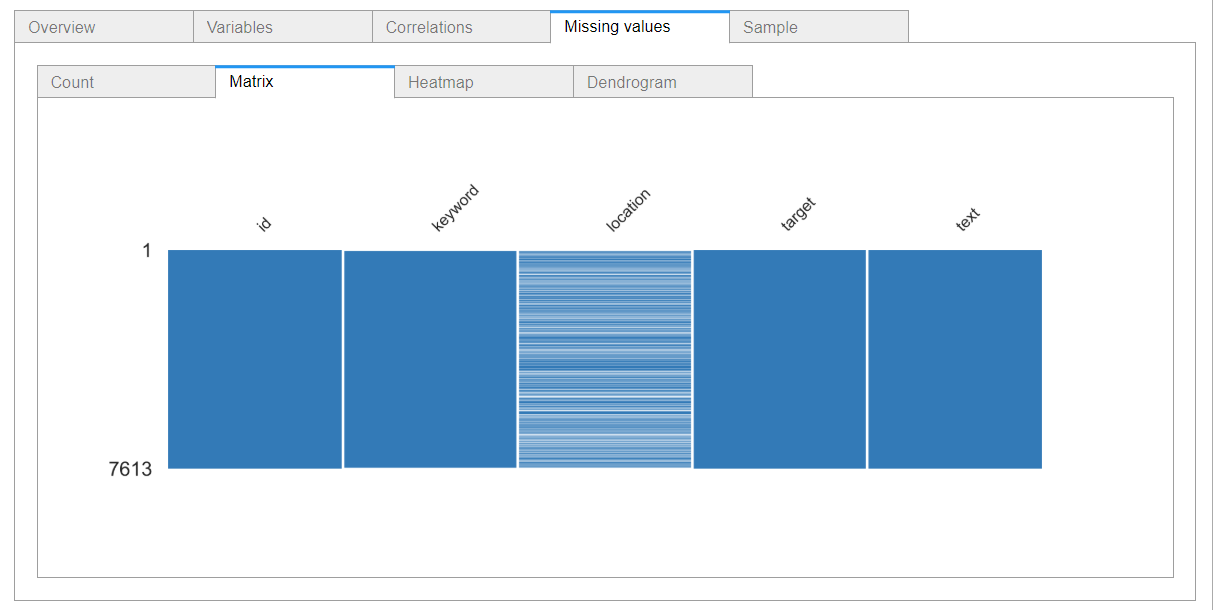
네번째 Missing values에서는 NA가 있는 변수에 대해 파악할 수 있다.
마지막 Sample에서는 각 데이터 미리보기 (head / tail 느낌)

데이터 EDA가 전반적으로 되어 있어 데이터 전처리를 하기 전에 꼭 해보면 좋을 것 같다.
반응형
'DATA SCIENCE > VISUALIZATION' 카테고리의 다른 글
| [Tableau] Rounded bar chart 만들기 (0) | 2020.03.20 |
|---|---|
| [Tableau] 달력 차트 만들기 (0) | 2020.03.20 |
| [Tableau] 날짜 기준 매개변수 생성하기 (0) | 2020.03.20 |
| [R] 색상 이름 (0) | 2020.02.18 |
| [Python] kaggle bike 데이터를 이용한 pandas 전처리 / seaborn 시각화 (0) | 2019.06.22 |

